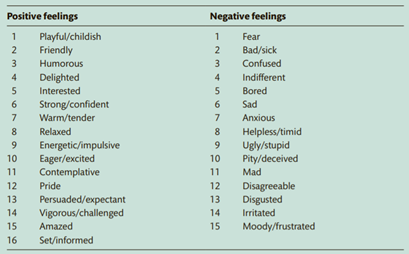
solution
Ice cream ‘hot spots
Häagen-Dazs Shoppe Co. (www.haagendazs.com), with more than 850 retail ice cream shops in over 50 countries, was interested in expanding its customer base. The objective was to identify potential consumer segments that could generate additional sales. It used geodemographic techniques (as discussed in Chapter 5), which are based upon clustering consumers using geographic, demographic and lifestyle data. Additional primary data were collected to develop an understanding of the demographic, lifestyle and behavioural characteristics of Häagen-Dazs Shoppe users, which included frequency of purchase, time of day to visit café, day of the week and a range of other product variables. The postcodes or zip codes of participants were also obtained. The participants were then assigned to 40 geodemographic clusters based upon a clustering procedure developed by Nielsen Claritas (www.nielsen.com). Häagen-Dazs compared its profile of customers with the profile of geodemographic classifications to develop a clearer picture of the types of consumer it was attracting. From this it decided which profiles of consumer or target markets it believed to hold the most potential for additional sales. New products were developed and advertising was established and profiled to target specific consumer types.
"Looking for a Similar Assignment? Get Expert Help at an Amazing Discount!"